
Suggest categories, tags, and entities from post content using either a natural-language API or vector embeddings against the existing taxonomy.
How it works
Content tagging — the original ClassifAI feature, originally built around IBM Watson — analyses the body of a post and proposes terms across the standard WordPress taxonomies. There are two distinct strategies behind the same UI. The Watson NLU strategy returns a structured set of categories, keywords, concepts, and entities, which ClassifAI maps to dedicated taxonomies it registers (Watson Categories, Watson Keywords, Watson Concepts, Watson Entities). The embeddings strategy turns the post into a vector and compares it against the embeddings of every existing term in the taxonomies you have selected, returning the closest matches as suggestions; the model can only ever propose terms that already exist on the site, which is what most editorial teams actually want.
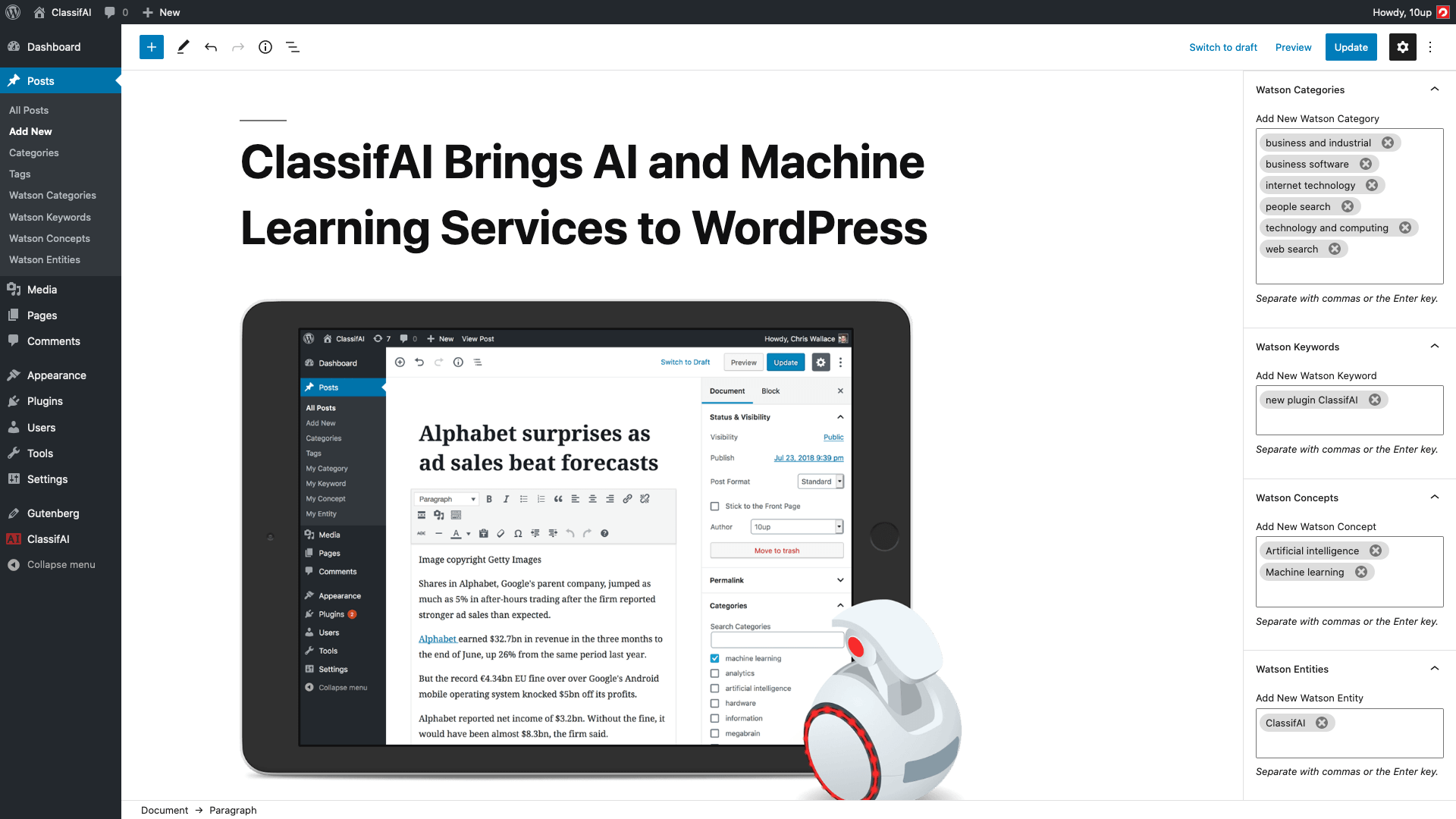
Configuration
- Which taxonomies are in scope for tagging suggestions.
- Confidence threshold for auto-applied terms (anything below is held for editorial review).
- Provider and model selection.
- Allowed roles and an allowed-users list for granular access control.
Providers
- IBM Watson Natural Language Understanding
- OpenAI Embeddings
- Azure OpenAI Embeddings
- Ollama Embeddings (locally hosted)
Use cases
- Newsrooms with sprawling tag taxonomies that need consistent classification across many writers.
- Editorial archives where retroactive classification is otherwise prohibitively manual.
- Sites using ElasticPress or facets that depend on accurate, consistent taxonomy terms.